High-dimensional data reduction using Machine Learning can help find the commonalities hidden in big data.
The ability to collect data is constantly exponentially evolving and there has a been a surge in exploring the world of ‘Big Data Analytics’ in environmental forensics. This coupled with the high-throughput and fast turn around times for results have emboldened scientists to explore datasets in their entirety instead of comparing which parameters may be considered above guidelines. Outside of environmental forensics this relationship with big data has already become the norm. In genomics, gene expression can be now done simultaneously on millions of cells producing gigabytes of data in the form of base pairs A, G, C, T. With billions of bases in just one human DNA strained we can see how large these numbers become. Analytical chemistry is on the route of experiencing these surges in data set sizes as advancements have accounted for a vast increase in the amount of chemicals analyzed. For instance, multi-dimensional chromatography can now resolve thousands of compounds from analysis of a single sample.
As consultants tied into the field of environmental forensics and analytical chemistry how do we brace ourselves for the future surge of big data? We need to follow in the steps of the pioneering data scientists and embrace the steps they are taking to interpret these complex multivariant data sets. One of the key approaches we will focus on in this blog is the ability to reduce the dimensionality of these data sets to find the commonalities hidden through the use of Machine Learning. The machine learning algorithm of focus for this blog will be looking at using t-distributed stochastic neighbor embedding (t-SNE) as your primary dimensionality reduction technique.
What is t-SNE?
t-SNE is a non-linear machine learning algorithm that reduces dimensionality by paring multivariant objects between how similar their location is in multivariant space (t-distributed variant). Similar to Principal component analysis, the aim of t-SNE is to cluster these multivariant samples based on their similarity and identify key trends bringing them together.
Cool examples of t-SNE:
Right now, machine learning and t-SNE specifically are the hot trend in the world of data science and the popular kids at school such as Netflix, Facebook and Google have already gotten themselves involved in it. For instance, Google has complied every image associated with arts and culture to a google cloud storage. They have taken all these different images and represented their associated taglines and even color schemes as different multivariant parameters and run a t-SNE to separate the categories of all arts and culture images in human history Google t-SNE.
Why should t-SNE be embraced in environmental forensics?
Although the cool kids at school are all on board with embracing machine learning in data interpretation, not everyone has jumped on the trend. Whether it be nostalgia or a hipness to do things, “the old school” way, many consultants tend to stay connected with the approaches they’ve gained from their professors at school or mentors at work. Formal education is absolutely required to understand the fundamentals of the scientific approach, but the corner stone to excelling as a subject matter expert is to stay current with the innovations happening within your field and the general scientific community.
These modern machine learning techniques and t-SNE in specific offer a great deal of benefits for the consultant including:
- Speed and efficiency. Looking through every column of data proves to be a very tiresome approach to data interpretation. In the situation where you can have hundred of different chemical species (PCBs for instance), comparing each individual combination of column together is not feasible and extremely costly. Comparing for instance every combination of 100 columns (100100 for those inclined to do the math) can take a consultant several hours to do, while machine learning algorithms can accomplish these in seconds depending on the data size. Profits are maximized when consultants only bill clients for consulting and not data restructuring.
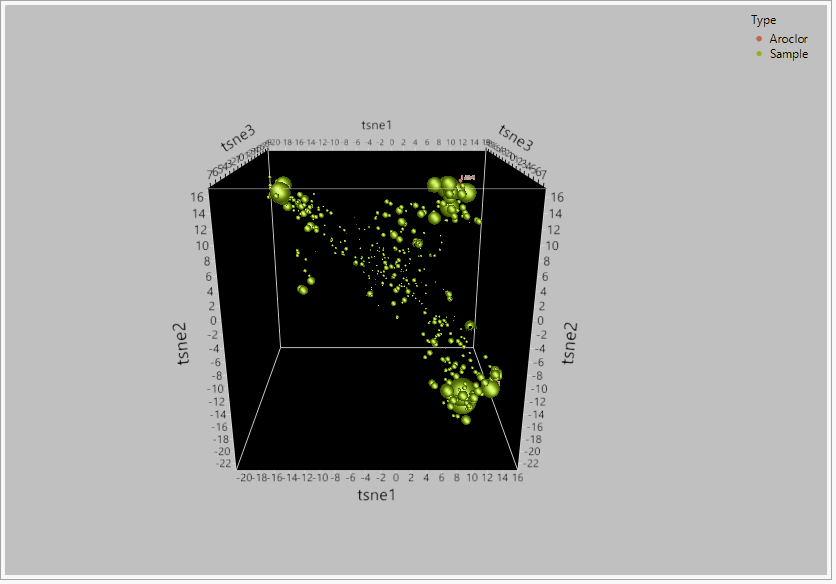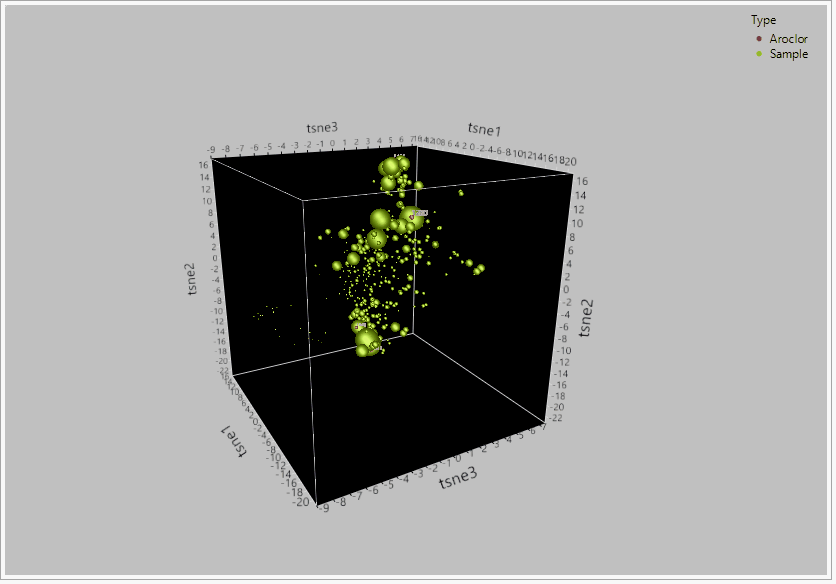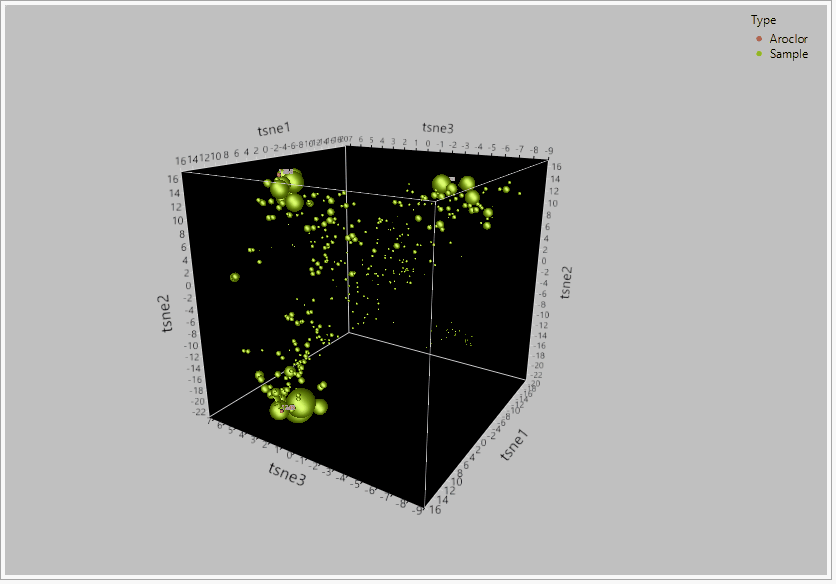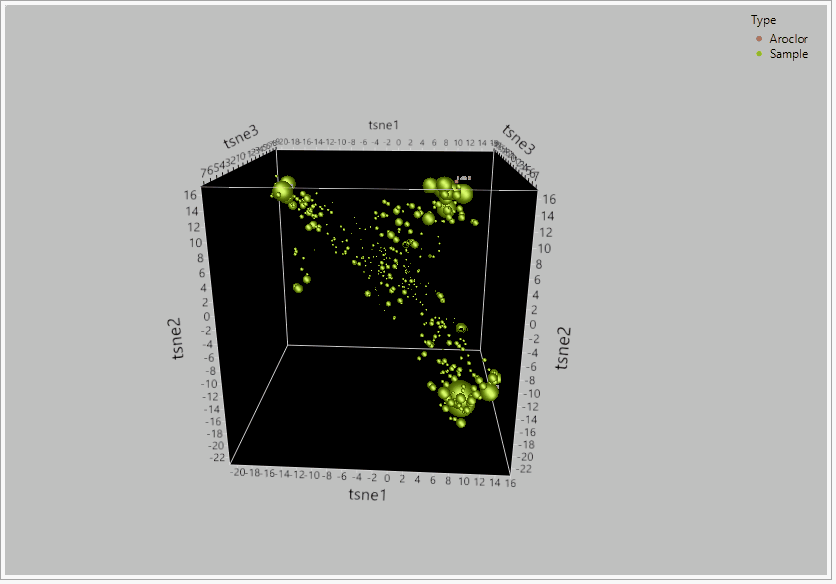
- Better understanding of chemical data Global Structure. Here I’ll define global structure as the complete variability between all the different chemical parameters and/or species within the data set. Traditionally, reduction techniques employ linear approaches such as PCA. The underlying issue with using linear regression is that it cannot completely capture the entirety of the multi-dimensional data structure. More often than not if large magnitude differences are present in the data set (as often the case between chemical species in environmental data), the reduction of dimensionality comes at the cost that both the principal comments and eigenvectors are constrained to linear model that cannot account for all the variability. The result of this is a score plot that may only contain a fraction of the variance and the remaining variability is missing within subsequent principal components. t-SNE however is a non-linear dimensionality reduction accounting for the maximum potential variability in the data set. t-SNE’s ability to rank order these points lead to the greater increased in variability explained with the data set and can cluster your data more effectively.

Figure 1 – PCA dimensionality reduction on a dataset for 209 congeners of PCBs between 435 samples and reference aroclor standards. The PCA for this data set could only explain around 50% of the variability between the different PCB congeners and consequently could not differentiate between the groupings of samples.
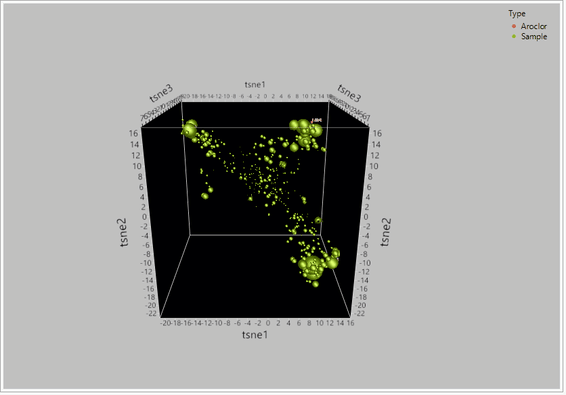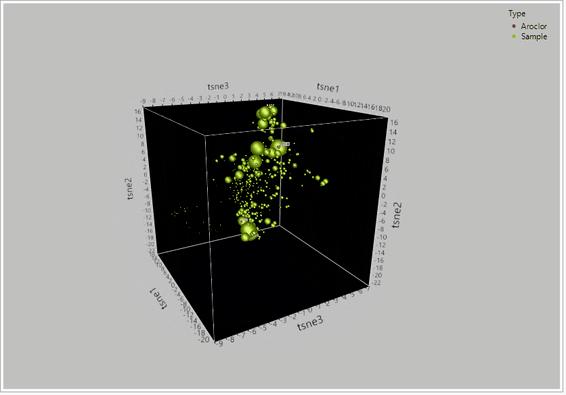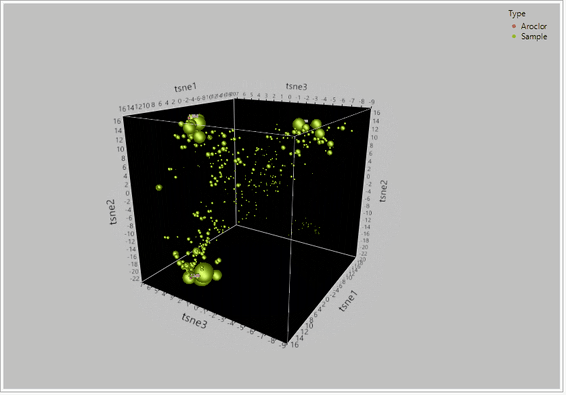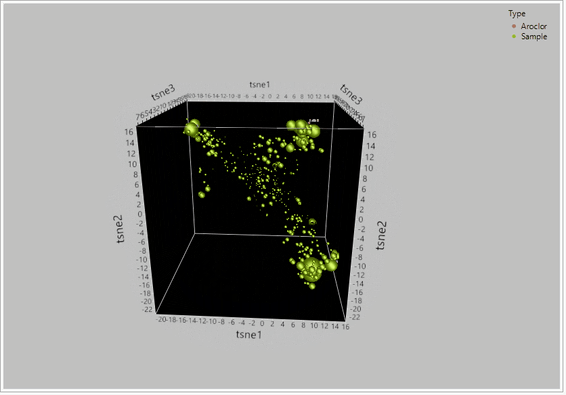
Figure 2 – TSNE PCA dimensionality reduction on a dataset for 209 congeners of PCBs between 435 samples and reference aroclor standards. When the global structure between the 209 congeners was retained, t-SNE effectively grouped the compounds into their likely sources based on their relative clustering around the aroclor standards.
What can Chemistry Matters provide:
Here are Chemistry Matters we aim to stay relevant to the evolution of data science within the field environmental forensics. Not only are we relevant to the trends in our discipline, we seek to employee the trends set out by the “popular kids” and pioneer a data driven focus in the field of environmental forensics.
References:
Google Arts & Culture t-SNE Interactive: https://artsexperiments.withgoogle.com/tsnemap/#-1883.04,1260.49,-3741.36,-762.32,0.00,-4354.86
The art of using t-SNE for single-cell transcriptomics: https://www.nature.com/articles/s41467-019-13056-x
-1.png?width=859&name=Sample%20%231%20(2)-1.png)
.jpg?width=859&name=Archery%20photo%20(3).jpg)